Elsa Design
By Daniel Wilkerson and Scott McPeak
This file is an attempt to articulate the design of Elsa to someone who would like to work on it.
Elsa attempts to parse C and C++:
Note that Elsa does not try to reject all invalid programs. The checking that Elsa does is primarily for the purpose of ensuring that its interpretation of the code is correct. For example, Elsa does check that argument types match parameter types (which helps to catch bugs in Elsa's type computation logic, and is required to determine where user-defined conversions take place), but does not enforce the access control rules ("public", "private", etc.) of C++. Ideally, Elsa eventually will check such things, but it is not a priority for the forseeable future.
Elsa is extensible; that is, one may add additional syntactic features to the language being parsed, without directly modifying the files that define the base language. This "base-and-extension design pattern" occurs frequently in the design of Elsa; for example, it is used to support for C99 and GNU extensions to C++. The intent is to allow users to modify Elsa almost arbitrarily, but still be able to keep up with the Elsa release cycle.
There are several stages to the processing of an input file:
Lexing (a.k.a. scanning) is the process of partitioning a flat sequence of characters into a sequence of tokens. In addition to being a partition, the tokens represent classifications of the partitions: the character sequence "123" might be called an "integer literal", and the sequence "abc" an "identifier". The Lexer discards comments and whitespace (rather than passing them on to the parser).
As mentioned above, much of the Elsa design involves extension mechanisms, and the Lexer is no exception. A base description is combined with one or more extension descriptions to arrive at the full lexical language:
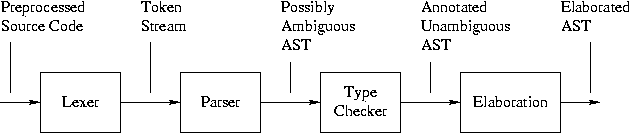
Above, solid lines indicate direct flow, and dashed lines indicate where one file is #included by another (i.e. both directly flow into a program further down but not shown). Files are shown in ellipses and programs are shown in rectangles.
cc.lex is the base lexer description. It is written in the Flex language. gnu.lex is an extension lexer description; it contains definitions for GNU and C99-specific lexical elements. These two descriptions are combined with merge-lexer-exts.pl to produce lexer.lex. lexer.lex is subsequently read by Flex to generate lexer.yy.cc, a C++ module that does the actual scanning.
Build process invariant: Any time a script or tool produces a text file, the build process marks it read-only. This makes it harder to accidentally edit a file that is automatically generated. Thus, all the files in the diagram above that are the output of a rectangle are marked read-only.
Unlike Bison, Elkhound does not automatically choose the mapping from lexer token codes (like "4") to conceptual lexical elements (like "integer literal"). So the Elsa build process uses a script called make-token-files to assign the mapping. It uses the token descriptions supplied by cc_tokens.tok and gnu_ext.tok.
lexer.lex specifies how to partition the input characters into tokens. Most of the actions are straightforward. One tricky point is the notion of "separating tokens" and "nonseparation tokens", which is explained at the top of lexer.cc. Another is that "#line" directives are handled by recording them with the hashline module, which can then be used to map a raw input source location to a the location designed by the #line directives.
The baselexer module is responsible for coordinating the activity of a Flex lexer and an Elkhound parser. It inherits from LexerInterface (lexerint.h), which defines three fields (type, sval, and loc) that the Elkhound parser reads. BaseLexer updates these fields during lexing according to what the lexer actions do.
BaseLexer is extended by the lexer module, which defines the Lexer class, which contains the methods that the lexer actions invoke.
If you would like to see the results of just lexing an input file, the tlexer program (tlexer.cc) will read in a preprocessed C/C++ source file and print out the sequence of tokens that would be yielded to the parser.
Parsing is the process of converting a token stream into an Abstract Syntax Tree (AST). In Elsa, the AST produced by the parser is not necessarily a tree at all, but a Directed Acyclic Graph (DAG) in general, because of ambiguities. However, we still call it an AST.
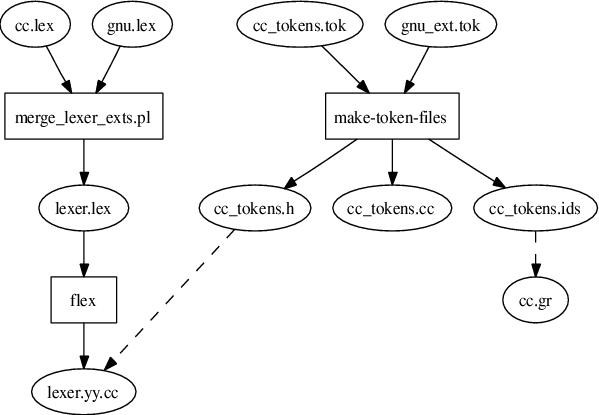
The parser is written in a mixture of Elkhound and C++; the Elkhound language defines how terminals, nonterminals and productions are defined, while the reduction actions associated with the productions are written in C++. The parser description is a combination of three files:
There are three output files from Elkhound:
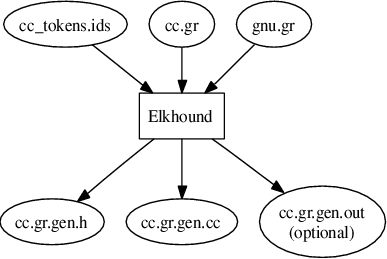
The AST is described by a language that is input to the astgen tool. The description is comprised of several files:
The output files are:
Most of the parser actions are straightfoward: combine the AST elements that comprise the production right-hand side (RHS) into a single AST element that represents the left-hand side (LHS).
Two issues are explained at the top of cc.gr are the various source of names, and handling of destructive actions.
Most instances of syntactic ambiguity are handled by using the ambiguity fields of certain AST nodes to explicitly represent the different alternatives. The type checker then has the responsibility for picking one alternative. For example, the ambiguous syntax "return (x)(y);" would be represented as shown in the following diagram, where the cast interpretation "return (x)y;" is shown in green, and the function call interpretation "return x(y);" is shown in purple. Note that the nodes for "x" and "y" are shared by both interpretations.
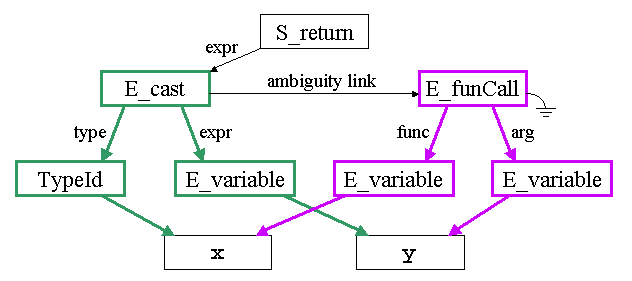
A few instances of ambiguity are handled at parse time, rather than deferring to the type checker as in the diagram above. This is done by writing keep functions that cancel a reduction if it can be determined that the syntax giving rise to the reduction has another (better) interpretation. For example, there is an ambiguity in template parameters because "<class T>" could be a type parameter called "T", or it could be a non-type parameter of (existing) type "class T" but with no parameter name. As the Standard specifies that this is always a type parameter, the reduction for non-type parameters cancels itself if the type is like "class T" (see the TemplateParameter -> ParameterDeclaration reduction and the associated keep function in cc.gr).
The tracing flag "printAST" to ccparse will print the (possibly ambiguous) AST as it exists before type checking.
The tracing flag "parseTree" will print the full parse tree. The parse tree shows the structure of reduction action calls by replacing every reduction action with one that builds a generic parse tree node out of its subtrees. This is useful for debugging ambiguities, since it shows exactly what happens in the parser, without interference from the actual reduction actions.
The type checker (cc_tcheck.cc) does five major jobs:
The fundamental data structure on which the type checker does its work is the AST, documented in cc.ast.html.
The tracing flag "printTypedAST" will print the AST after type checking.
AST disambiguation means choosing a single interpretation for AST nodes that have more than one (i.e. a non-NULL ambiguity field). Then, the surrounding AST nodes are modified to reflect the chosen choice and forget about the others. The tracing flag "disamb" will report disambiguation activity.
Most disambiguation is done by the generic ambiguity resolver, in generic_amb.h. The resolveAmbiguity function simply invokes the type checker recursively on each alternative by invoking the mid_tcheck method. If exactly one alternative successfully type-checks (i.e. does not report any errors), then that alternative is selected. The ambiguity link for the selected node is nullified, and the selected node returned so the caller can update its AST pointer accordingly. It is an error if more or less than one alternative type-checks.
As recursive type checking can sometimes involve doing computations unrelated to the disambiguation, such as template instantiation, at certain points the type checker uses the InstantiationContextIsolator class (cc_env.h) to isolate those computations. They will only be done once (regardless of how many times they occur in ambiguous alternatives), and any errors generated are not considered by the ambiguity resolver.
Not every ambiguous situation will be resolved by the generic resolver. In particular, there is a very common ambiguity between E_funCall and E_constructor, since the parser can almost never tell when the "f" in "f(1,2,3)" is a type or a function. If the generic procedure were used, this would lead to exponential type checking time for expressions like "f1(f2(f3(...(fN())...)))". Since this disambiguation choice depends only on the function/type and not the arguments, Expression::tcheck explicitly checks for this case and then just checks the first component by invoking the inner1_tcheck method. Once the selection is made, inner2_tcheck is invoked to finish checking th argument list.
There are a few other ad-hoc disambiguation strategies here and there, such as for deciding between statements and declarations, and resolving uses of implicit int (when K&R support is enabled).
Declared entities are represented by Variable objects (variable.h). In general, lookup is the process of mapping a name (which is a string of characters) and a context (scopes, etc.) to a Variable. AST nodes that contain names subject to lookup, such as E_variable or E_fieldAcc, contain a var field. The var field is initially NULL, and the type checker sets it to some non-NULL value once it figures out which Variable the name refers to.
Though the C++ standard in principle gives all of the rules for exactly how lookup should be performed, in practice it can be difficult to map those rules into an implementation. The auxilliary document lookup.txt explains how the rules in the standard are implemented in Elsa.
There are many kinds of entities represented by Variables, as shown in the following diagram. The rectangles and arrows represent a kind of inheritance hierarchy; e.g., a Class is one of the type-denoting Variables (note that this is only conceptual inheritance; in the implementation, there is just one class called Variable). The ellipses are data fields attached to Variables.
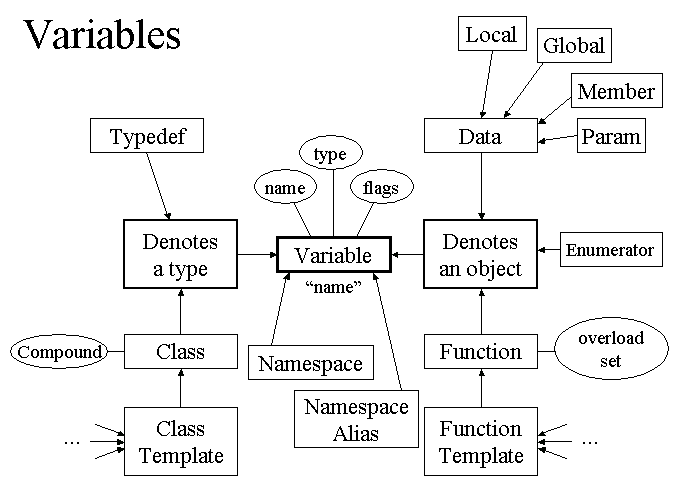
On the left half of the diagram are names corresponding to types, and on the right half are non-type entities. Types are introduced by a typedef or by a class declaration. Non-types are introduced by a variable declaration, or a function prototype or definition. A few oddballs, such as enumerators and namespaces, round out the set. The neighborhoods of the class and function template boxes are expanded in a later diagram, below.
Every Variable has a name (but it might be NULL), a type (only NULL for namespaces), and some flags. The name is how the entity is found by lookup. The type is either the denoted type (for type entities) or the type of the variable (for non-types). The flags say what kind of entity a given Variable is; by interrogating the flags, one can determine (for any given Variable object) to which box in the diagram it belongs.
It may seem odd that so many kinds of entities are represented with the same Variable class. The reason is that all of these entities are looked up in the same way, and all of these entities' names hide each other (when scopes are nested), so the Variable is the fundamental element of a Scope (cc_scope.h). The word "name" in quotes suggests this connection, as all of these entities correspond to what the C++ Standard simply calls a "name".
In C++, function names and operators can be overloaded, meaning there is more than one entity with a given name. The name is mapped to an entity by considering the context in which it is used: for a function call, the argument types determine the overloaded entity; when taking the address of a function, the type of the variable receiving the address determines which entity has its address taken; etc.
Elsa represents overload sets by having a single representative Variable contain a linked list, the contents of which are the overload set (including the representative itself). Initially, typechecking an E_variable or E_fieldAcc that refers to an overloaded name will set the node's var field to point at the set representative. Later, it uses the call site arguments to pick the correct entity. Then, the E_variable or E_fieldAcc node's var field is modified so that it points directly at the chosen element.
At the moment, there is no way to distinguish between a Variable object denoting an overloaded set, and a Variable object denoting just the specific entity that happens to be the set representative, so this distinction must be inferred by context (i.e. before overload resolution has occurred, or after it). This design might be changed at some point.
When Elsa finds that an operator is overloaded, it again uses the arguments to select the proper operator. If the selected operator is a built-in operator, the (say) E_binary node is left alone. But if a user-defined operator is chosen, then the node is changed into an E_funCall to reflect that, semantically, a function call occurs at that point. One way to observe this change is to pretty-print the AST (see pretty printing).
Expressions (and a few other nodes) have a type associated with them. The type checker computes this type, and stores it in the type field of the node.
Types themselves have internal structure, which is explained in cc_type.html.
When an object is (say) passed as an argument to a function, depending on the types of the argument and parameter, an implicit conversion may be required to make the argument compatible with the parameter. This determination is made by the implconv module. Among the kinds of implicit conversions there are user-defined conversions, conversions accomplished by calling a user-defined function. When Elsa finds that user-defined conversion is required, it modifies the AST to reflect the use of the conversion function, as if it had been written explicitly.
Bug: While Elsa currently (2005-05-29) does all the necessary computation to determine if a user-defined conversion is needed, in some cases it fails to rewrite the AST accordingly. This will be fixed at some point (hopefully soon).
Elsa does template instantiation for three reasons. First, instantiation of template class declarations is required in order to disambiguate the AST, since a template class member can be either a type or a variable name, and that affects how a use of that name is parsed.
Second, instantiation is required to do annotation such as for expression types, since the type of an expression involving a member of a template class is dependent on that template class's definition.
Finally, instantiation of function templates (including members of class templates) lets analyses ignore the template (polymorphic) definitions and concentrate on the (monomorphic) instantiations, which are usually easier to analyze.
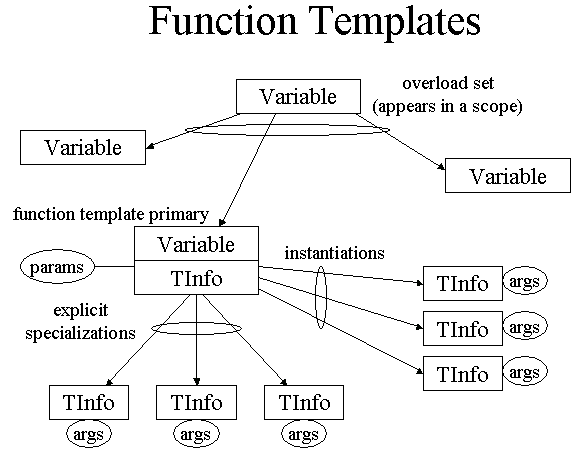
Function templates are represented with a Variable (variable.h) to stand for the function template, and an associated TemplateInfo (template.h) structure to remember the template parameters (including default arguments), and any instantiations that have been created.
The TemplateInfo class acts as an extension of the Variable class; every TemplateInfo is associated with a unique Variable. It would have been possible to make TemplateInfo actually inherit from Variable, and at some point the design may be changed to do just that.
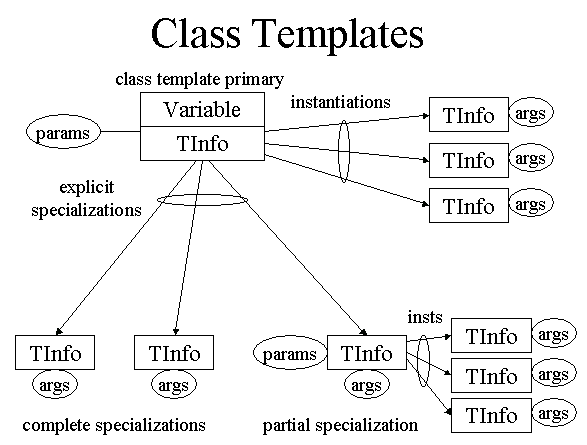
In the following diagram, rectangles represent (separate) objects that exist at run-time, and arrows represent pointers among those objects. An ellipse overlapping several arrows represents a list of pointers.
Class templates are also represented by a Variable/TemplateInfo pair. The wrinkle is that template classes can have partial specializations, user-provided classes for use when the template arguments match some given pattern (for example, a generic Vector template might have a partial specialization for Vector<T*> that uses a more efficient representation):
Function templates are instantiated as soon as a definition and a use (the use supplying the template arguments) have been seen. This is done by calling Env::instantiateFunctionTemplate (template.cc), which returns a Variable/TemplateInfo pair that represents the instantiation. If the instantiation has already been made, the existing one is returned. If not, the template definition AST is cloned (deeply copied), the template parameters are bound to their arguments, and the entire definition re-type-checked.
Class templates are instantiated as soon as a use is seen; a program is ill-formed if a definition has not been seen by the time of first use. Instantiation is done by calling Env::instantiateClassTemplate (template.cc). As above, if the instantiation already exists, it is re-used; otherwise the template definition is cloned and re-type-checked.
Function members of class templates are not instantiated until a use of the member is seen. For members whose definition appears "inline" in the class body, the MR_func::f field points at the uninstantiated template body. The body will be cloned and type-checked only when it is instantiated. One consequence of this design is that analyses (usually) need to avoid looking at such uninstantiated members; one way to do this is by using ASTTemplVisitor (cc_ast_aux) to do the traversal, as it automatically skips such methods.
The C++ Standard has fairly elaborate rules for deciding when a type or a name in a template definition is dependent on the template parameters. Furthermore, it specifies that names and types that are not dependent must be looked up in the context of the original template definition, not the instantiation context (as is the case for dependent names).
To implement this (and to disambiguate template definition ASTs), Elsa type-checks function template definitions in advance of any instantiation. A dependent type is represented by the ST_DEPENDENT pseudo-type (see enum SimpleTypeId in cc_flags.h).
Furthermore, while type checking the template definition, if a name lookup is determined to not be dependent, the nondependentVar field is set to the same thing as the var field (both are fields of AST nodes that have names subject to lookup). Later, when an instantiation is created, the nondependentVar value is preserved by cloning, and used instead of doing a new lookup, if it is not NULL.
When a class template instantiation is requested but one or more arguments is dependent, a PseudoInstantiation type (template.h) is created. This is more precise than simply yielding ST_DEPENDENT, and that precision is necessary in some cases, and much cleaner than doing a full "instantiation" with incomplete information.
Similarly, when type checking a template definition, the template type parameters are bound to (unique) instances of TypeVariable (template.h) objects.
Elsa will perform various forms of post-processing on request.
Tracing flag "printHierarchies" will print inheritance hierarchies in Dot format. Interesting in that virtual inheritance is represented properly; for example in/std/3.4.5.cc yields 3.4.5.png.
Tracing flag "prettyPrint" will print out the AST as C++. One use of this feature is to do some analysis on the source code, then print it out with analysis results intermixed as annotations that can then be fed to another analysis tool. Bug: (2005-05-29) Not all C++ constructs are correctly printed yet.
Each phase of Elsa has some degree of support for extensions, as documented in this section.
First, let me distinguish compile-time extensions from run-time extensions. Compile-time extensions let a programmer add new features to a program without having to modify that program's original source code; but the program must be recompiled (possibly with an altered build process) to incorporate those extensions. In contrast, run-time extensions can be added by an end-user without recompilation; browser plugins are an example.
While Elsa does have a few run-time extension mechanisms such as the TypeFactory, the majority are compile-time mechanisms. The rationale is that I can support a much wider range of extensions that way, and given that Elsa is more or less intended to be research infrastructure, there is no compelling reason for run-time extensibility. Note that the OpenC++ parser is designed for run-time extensibility.
In the limit, one need not explicitly design for compile-time extensibility at all, since programmers could simply write their extensions as patch files, and let patch incorporate them. However, this would be far from ideal, since patch files are fragile in the face of changes to the underlying source, and the toolchain (compiler error messages, source-level debuggers) would be unaware of them. So the general Elsa strategy is to design ways that programmers can write extensions with the following properties:
Unfortunately, not every extension mechanism used in Elsa has all of these properties. I will point out which properties hold below.
New token types can be added by creating a .tok file and arranging to feed it to the make-token-files script. The effect of this is simply to define names and aliases for tokens, such that the lexer and parser can refer to them coherently. Flaws: not toolchain-aware. (Example: gnu_ext.tok)
New lexical rules can be added by creating a .lex file and arranging to feed it to the merge-lexer-exts.pl script. This script textually inserts the extension into a combined flex input file, with extensions coming before the original rules so as to be able to override them. Flaws: not toolchain-aware, cannot delete origial rules (can leave spurious warnings). (Example: gnu.lex)
New syntactic constructs can be added by creating a .gr file and passing it on the elkhound command line. The new grammar consists of the union of the productions from the original and the extension(s). This is the cleanest of all the extension mechanisms, having all of the desired extension properties listed above. (Example: gnu.gr)
When new syntactic constructs are introduced, they typically need new AST nodes to represent them. New AST nodes can be added by creating a .ast file and passing it on the astgen command line. The effective AST spec is the union of the base and all extensions. Flaws: astgen should emit #line directives that point into the respective .ast files (this is not a flaw with extension per se, but astgen in general). (Example: gnu.ast)
New Type classes can be added by creating new subclasses of AtomicType and Type (cc_type.h), and implementing the appropriate virtual methods. Operations on the new types can be defined by creating a subclass of Env (cc_env.h) and overriding some of its methods. Flaws: not very powerful; you can only change behaviors for which hooks are already provided.
Type checking for new AST nodes can be added simply by adding a new C++ source file that implements the tcheck methods for the new nodes. Flaws: hard to do context-dependent behaviors. (Example: gnu.cc)
New fields and methods can be added to the Type superclass by replacing the definition of Type by defining the TYPE_CLASS_FILE macro. See cc_type.html, Section 6 for more information. Flaws: can only change the Type class, not others.
Finally, the plan is to add a generic source code patcher that operates at a higher level and is more robust than patch. This would let users do things like rename functions, insert snippets of code into functions, add members to classes, etc. However, that mechanism is still quite experimental and so not yet shipped with Elsa. Flaws: vaporware.
Elaboration is done by the ElabVisitor class (cc_elaborate.h), which could be extended with the usual inherit-and-override C++ idiom. See the next section for more information about visitors.
Within Elsa, the intent is that users write new post-processing analyses and plug them in by simply copying and modifying main.cc. This gives users maximal control over how an Elsa-based analysis interacts with the outside world. Flaws: ad-hoc.
Alternatively, the Oink framework (based on Elsa) provides a more systematic architecture for integrating post-processing analyses, both with Elsa and with each other. Flaws: analysis must fit into the framework.
For implementing an analysis, programmers are of course free to simply write a custom traversal similar to the type checker (cc_tcheck.cc). However, for many analyses it is convenient to extend the ASTVisitor, a class created automatically by astgen. A simple example is the NameChecker in main.cc, which does some simple processing at each Expression node. Note that your visitor can traverse the full AST by inheriting from ASTVisitor, or traverse only the "lowered" AST (e.g., skipping templates and only looking at the instantiations) by inheriting from LoweredASTVisitor (cc_ast_aux.h). Flaws: visitors are simple, but make context dependence difficult to achieve.
This section explains what policies and procedures are in place to try to ensure that Elsa is "correct", in the sense that it accepts valid C++ input code and produces an annotated, elaborated AST that accurately reflects the syntax and semantics of that code.
(I do not call this section "Quality Assurance" because I am talking about procedures followed by developers, rather than the processes and measurement techniques that might be used after the fact.)
Most of what is outlined here is standard practice, and the potential scope of "correctness assurance" is huge, so I'll try to confine this to things directly relevant to Elsa.
"Testing" is the process of searching for evidence of a defect. The input to testing is a program, and the output is a testcase (for Elsa, a C++ input file) such that running the program with that testcase causes the program to demonstrably misbehave.
The central artifact of the Elsa testing effort is the regrtest ("regression test") script. This script runs Elsa (via the ccparse driver program) on hundreds of input files, checking that it accepts the valid inputs and rejects the invalid ones. In some cases there are known bugs in Elsa; corresponding inputs are marked with "failparse" (or similar), and regrtest expects Elsa to fail those tests. It should be run before every commit.
Invalid inputs are handled by adding lines of the form
//ERROR(n): some-invalid-syntaxto an otherwise valid input file, where
Ideally, a regrtest testcase should have these properties:
Of course, these are not absolute rules, but they help to explain why we don't, say, put the entire preprocessed Mozilla codebase into regrtest.
Somewhat contradicting the above, at the end of regrtest there are several "big" tests. These are included both as a sanity check to make sure Elsa can parse a few big things, and as a performance test. However, if a bug in Elsa is revealed by one of these big tests, a minimized testcase should be added as well so that we are not unduly relying upon them.
Moreover, the general procedure is that no Elsa bug should be fixed without first adding a minimized testcase or extending an existing testcase. This has several benefits:
The Elsa developers rely heavily on the technique of minimization, which takes as input a testcase demonstrating an Elsa bug and produces as output a testcase that demonstrates the same bug but is as small as possible. This makes debugging easier and faster, and produces better testcases for inclusion in regrtest.
Typically, minimization is done with respect to two nominally opposing criteria:
We have considerable support for automating the minimization process. The Delta tool will minimize an input with respect to arbitrary criteria, and the test-for-error script provides the good/bad criteria above. The two are combined in the run-delta-loop script. These scripts may need to be modified to suit your particular use, or of course you can write your own.
Despite the automation, delta typically does not yield inputs that are adequately minimal. Usually, I let delta make a first pass, then I simplify the testcase a bit (by hand) in ways that delta does not know how, let delta run again, then finish up by hand. The goal here is to make it as easy as possible to comprehend the meaning/semantics of the testcase, so that the person trying to debug Elsa when that testcase fails has it as easy as possible.
There are several particular techniques that I have found useful when doing by-hand minimization after delta has done some work:
If all that Elsa were trying to do was recognize valid C++ and reject invalid C++, then the above techniques would be adequate. However, Elsa is also trying to compute an internal representation of the input that accurately conveys its semantics. For example, it computes the type of every expression in the program. What if that type computation is incorrect? It is sometimes possible to leverage a particular incorrect type computation such that it leads to spurious rejection, but doing so is ad-hoc and sometimes difficult.
Another approach would be to dump out the internal representation for a given source file and then compare that to a "known good" version of that dump. The problem with this approach is it is fragile: if the dump format happens to change, all the known-good dumps have to either be modified by hand, or discarded and regenerated (possibly accidentally saving wrong output in the process, if there is an unnoticed bug).
The Elsa solution to the problem of testing internal computations is to expose them in the source syntax. For example, to test that an expression's type is computed as expected, one can write (in/t0228.cc):
__checkType(sName, arr);and Elsa will test whether the types it gets for sName and arr are identical, and fail if they are not.
As a more interesting example, one can write (in/t0117.cc):
__getStandardConversion((Derived *)0, (Base const *)0, SC_PTR_CONV|SC_QUAL_CONV);and Elsa will attempt to convert Derived* to Base const *, and check that the conversion is a "pointer conversion" and a "qualification conversion" (terms defined in the C++ standard).
This approach ensures we can write robust tests for any feature, even those not directly connected to accepting or rejecting the input. The set of all such special functions is defined in the internalTestingHooks() function in cc_tcheck.cc.
Typically, Elsa users want to use Elsa to parse some specific piece of software. This requires some method for hooking into the build process to obtain all of the preprocessed input files.
One very simple method is to use the test-parse-buildlog script. Just build the package normally (say, with gcc), saving all of the output from make to a file. Then this script will read that file and use it to generate the preprocessed source files one at a time, feeding each to ccparse. This works pretty well if the goal is to ensure that Elsa can parse a given codebase.
However, it is not perfectly reliable (what if make is not echoing all of its commands, or if the package does not use make at all?), and it does not know how the translation units are assembled to form libraries and executables. For that, we use the build interceptor system. This replaces the system compiler with a script that squirrels away the invocation history, which can then be reconstructed to get an accurate picture of how the project as a whole fits together. (Note that build interception is something that a number of research groups have recently done. You may want to google for some alternatives.)
When building a large package, keep in mind that a significant fraction of the preprocessed source will come from the headers of whatever compiler is used to do the preprocessing, and the choice of which headers to use can affect both Elsa's ability to parse the code and your analysis' ability to reason about the results. There are a number of approaches:
Debugging is the process of mapping from evidence of a defect back to the defect itself, such as an erroneous line of code. Elsa has some features specifically designed to assist during debugging.
A generalization of printf-debugging, tracing flags let the user control exactly what kind of information is printed, by associating each debugging output command with a flag that must be enabled for that output to be seen. This is all implemented by the trace module in smbase.
Though there are many tracing flags (grep for trace in the source to find some), there is a set of flags that have become my standard set of flags to use when debugging a minimized input file:
To get these enabled automatically, I use a .gdbinit with the following contents (tmp2.cc is the filename I typically use for the testcase I'm currently working on):
file ccparse set args -tr error,overload,dependent,template,templateXfer,topform,matchtype,templateParams tmp2.cc set print static-members off break main break breaker run
Note: Because they are rather expensive, none of the tracing flags do anything unless Elsa has been ./configured with the -debug switch.
While running Elsa in a debugger, it is often convenient to be able to print values of variables. Of course, if the variable is a primitive type, then
(gdb) print xwill suffice. If x is not a primitive, then there is probably a routine that can be invoked to print it, typically one of the following forms:
(gdb) print toString(x) (gdb) print x->toString() (gdb) print x->asString() (gdb) print x->gdb()There is some rationale for the inconsistency, but I don't feel like getting into all that here. You will probably have to look at the declaration of the associated type to find out which to use.
The intent of the external documentation is to serve as something of a roadmap to Elsa, to inform programmers of where things are implemented and the assumptions behind those implementations. By "external", I mean "not in the source code".
Each of the four major components of Elsa (smbase, ast, elkhound and elsa) has a page documenting it and containing a brief description of its modules. They also have dependency diagrams to express some module interrelationships.
Further, some modules have their own documentation pages, such as cc_type.html and cc.ast.html. These pages explain high-level aspects of the module's design and interaction with other modules. They are also linked from the index.html page of the component.
Finally, there are some documents (e.g., lookup.txt) that cut across modules, describing some or other C++ language feature and its implementation in Elsa.
The source code contains a great deal of documentation in the form of comments. The comments are invaluable for quickly comprehending pieces of code. I'd rather lose the code than the comments.
The following paragraphs explain some of the commenting style used (and to be used) in Elsa. Perhaps I should make a separate style guide...
Every data member of every class has a comment. There are no exceptions. The data members are a shared API among all the code that can see them. It is essential that the meaning and purpose of each data member be clearly stated next to its declaration. Example:
// nesting level of disambiguation passes; 0 means not disambiguating; // this is used for certain kinds of error reporting and suppression int disambiguationNestingLevel;
Most functions have a descriptive comment. The comment can be associated with the declaration or the definition, depending on whether most call sites are from outside or inside the module. A function's comment should indicate the meaning of parameters and return values, and indicate the context in which it is called if that is relevant. Example:
// Remove all scopes that are inside 'bound' from 'scopes' and put them
// into 'dest' instead, in reverse order (to make it easy to undo).
void Env::removeScopesInside(ObjList<Scope> &dest, Scope *bound)
{ /*...*/ }
Group statements into paragraphs. Long sequences of imperative code should be organized into small blocks ("paragraphs") of related functionality, with a comment at the start saying the intent of that block, and blocks separated by blank lines. Example:
// connect tab A to slot B Tab *a = assembly.getTabA(); Slot *b = widgetFoo.leftSlot; a->insertInto(b); // now fold it in half Polygon p = assembly.bisection(); xassert(p.closed()); FoldManager::singleton()->fold(assembly, p); // and queue for boxing boxQueue.enqueue(assembly);
Do not duplicate comments for the same reason you do not duplicate code. If you must copy code, and it contains a comment, delete the comment in the copy, possibly replacing it with something like "as above".
Make liberal references to the standard. Pointers into the standard are very useful, for fairly obvious reasons. On the other hand, do not quote large pieces of it, as that merely clutters the code.
Make liberal references to the regression testcases. Most of the time, if a bug is fixed, a comment near the fix should mention the name of a testcase that demonstrates the bug. This helps to understand the code, since it provides a concrete example, and it makes testing related modifications easier because you know to test against the named testcases first.
Given the above discussion of documentation, it is reasonable to ask why I do not advocate the use of "documentation generators" such as doxygen. The main reason is I prefer not to have extra layers between the artifact I edit and the artifact I read. Extra layers mean more work to map across them, and they make it less likely that the documentation will be consulted and updated.
For documenting detailed behavior of the code, having the documentation right in the code means it is immediately available, and easy to update. For those times when I want to use special formatting or hyperlinks, I write a comment pointing at one of the separate HTML documents and put the formatting there.
For documenting archtecture-level behavior, a separate HTML file like this document works well. I wouldn't want this to be a great big doxygen comment. Nor do I want to use any of the latex-to-HTML translators, again for the reason of not wanting to introduce layers. I expect most people would read documentation like this in their web browser, not on paper, so producing postscript is not much benefit.
Finally, I feel that documentation generators can often be a distracting influence, as programmers can begin to act as if all that is needed to adequately document their code is to provide (say) doxygen attributes X, Y and Z; when in fact, the essence of good documentation is communication and substance, not form.
I am a believer in assertions. Their primary value is as part of the specification of the program, providing a formal language for codifying programmer assumptions.
Additionally, the run-time checking implied by an assertion serves to aid testing and debugging by helping to ensure that bugs have small witnesses. That is, given a particular bug in the program, the size of the input testcase required to demonstrate that bug is smaller when the program contains good assertions, and larger when it does not, because a failed assertion is an early manifestation of the defect. By reducing the size of the input required to witness a bug, a given level of testing effort will find more bugs, and make the program consequently more reliable.
When an assertion is added to the code, if it is not obvious from inspection of the surrounding code why the condition should be true, add a comment explaining it. Someday your assertion will fail, and when it does, you want to help the person who will have to figure out what has gone wrong and that the impact of that is. Example:
xassert(secondLast->qualifier); // grammar should ensure this
Within elsa, there are three main assertion-related functions, defined in xassert.h:
As mentioned at the top of this document, Elsa does not try to reject every invalid C++ program. We tacitly assume that the programs Elsa is asked to parse are already accepted by some C++ compiler, which hopefully enforces the language. However, enforcing some of the language's rules can help to expose bugs.
Anecdote: For a long time, Elsa would only try to convert argument types to parameter types if the function being invoked was overloaded. Checking the conversions is of course necessary to do overload resolution, but if the function is not overloaded then I figured it wasn't necessary. But the effect of this was that bugs in the type computation logic would only be revealed in circumstances where overloading was involved, meaning the testcases were complicated. When I went ahead and implemented checking for all function calls, at first there were a bunch of bugs that were revealed and had to be fixed, but from then on type computation bugs tended to have very simple witnesses, making it fairly easy to fix them. Lesson learned.
But to the extent Elsa does try to enforce the rules of the language, there is another problem: sometimes it properly rejects inputs that another compiler mistakenly accepts! In that case we may need to add a flag to CCLang (cc_lang.h) to emulate the bug.
However, we don't want to commit to emulating every bug in every compiler. Currently, our main goal is being able to parse code compiled with gcc on Linux, so we will support a bug if:
Rationale: If the bug is not present in gcc-3.x, then presumably the author of the code needing the bug is already under pressure to fix it since the all the major Linux distributions are using gcc-3. If the bug is not emulated by icc, and code needing it is rare, then we can file a bug report directly with the package author, explaining that the code is invalid and using icc to support that claim (icc is freely available and reasonably popular). Finally, we want to give users the option of preprocessing their code with the gcc-2 headers (because they are so much simpler), so we want to accept the code in those headers.
For the case of bugs in the gcc-2 headers, rather than implement full gcc-2 compatibility, I've just been adding little hacks that look at the names of the identifiers involved before relaxing the rules. This way I minimize the degradation of the language enforcement, while still accepting the code in those specific headers.
![]()
{kind=link}